4.4 容器日志

系列 - 容器与守护进程运维
目录
摘要
本实验将带你了解 Docker 容器日志的管理方法,包括最基础的
docker logs 命令,以及如何搭建 ELK 日志系统实现日志的集中收集和可视化。任务一:docker logs 命令
docker logs <容器名或ID> 可以用来查看指定容器的日志内容。例如:
docker logs supervisor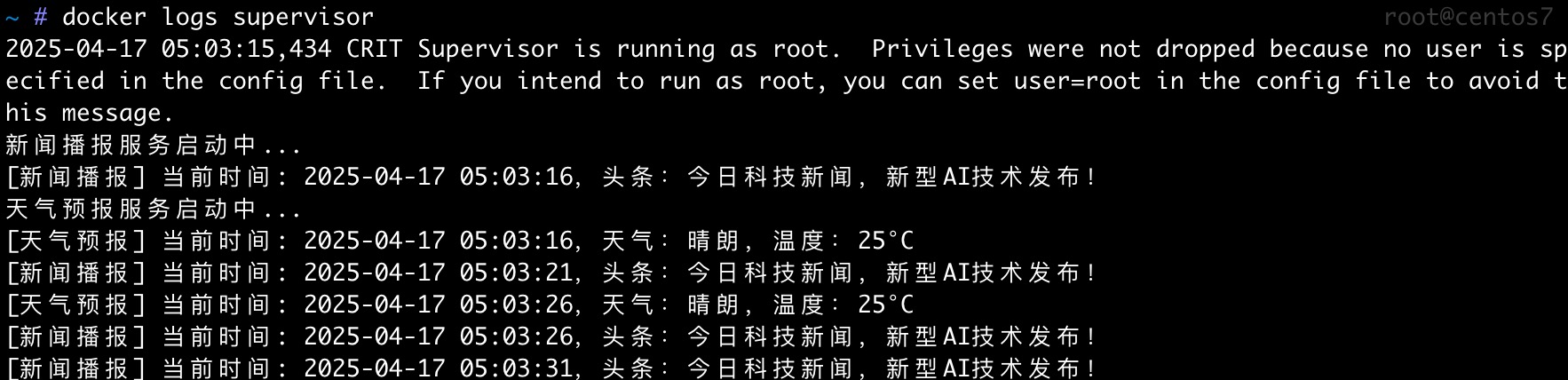
如果你想实时查看日志的最新输出,可以加上 -f 参数:
技巧:实时查看日志
加上
-f 参数后,日志会随着容器输出不断刷新,非常适合监控正在运行的服务状态。任务二:清理 Docker 日志
容器日志默认存储在 /var/lib/docker/containers 目录下。可以使用 find 命令快速查找所有日志文件:
find /var/lib/docker/containers -name "*.log"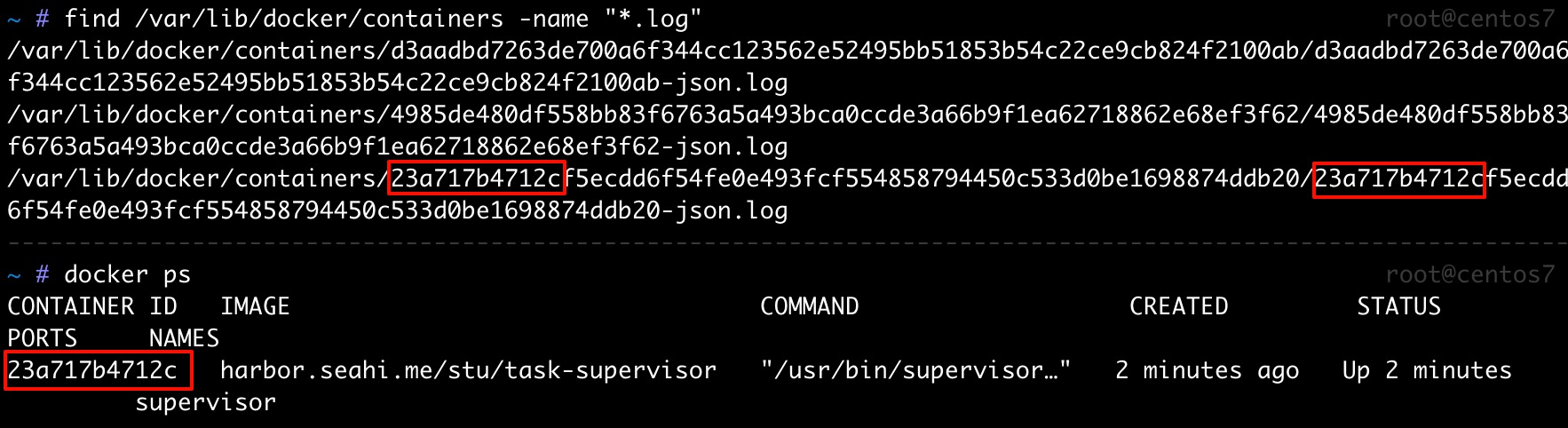
日志文件通常以容器的 ID 命名,如上图所示。
如果日志文件变得很大,可以手动清理,也可以用下面的小脚本批量清理:
#!/bin/sh
logs=$(find /var/lib/docker/containers/ -name *-json.log)
for log in $logs
do
echo "clean logs : $log"
cat /dev/null > $log
done
警告:清理日志注意事项
清空日志文件不会影响容器运行,但建议在业务低峰期操作,避免影响后续日志分析。
任务三:搭建 ELK 日志系统
ELK 代表 Elasticsearch、Logstash、Logspout 和 Kibana,是常用的日志收集、分析和可视化解决方案。
工作流程说明
Docker容器生产日志:学生完成作业
- 每个 Docker 容器就像班级里的学生
- 容器运行时会不断产生各种日志信息
- 不同类型的容器(Web服务、数据库等)产生的日志内容也各不相同,就像不同学生交不同科目的作业
Logspout:学委收作业
- Logspout 就像班级学委,收集每个学生的作业(日志)
Logstash:班主任处理作业
- 从学委手中接收所有收集到的作业
- 对作业进行标准化处理:
- 整理格式不规范的作业
- 添加批注和额外信息(如时间戳、环境标签)
- 过滤掉不重要或重复的内容
- 将不同格式的作业转换为统一标准
Elasticsearch:档案室归档存储作业
- 处理后的作业会被归档存储:
- 按容器类型(科目)分类
- 按时间顺序排列
- 按重要程度标记
- 提供强大的检索能力:
- 可以快速找到任何一个容器的日志
- 支持全文搜索和复杂查询
- 保存历史记录,便于追踪问题
Kibana:教务处提供查询和分析
- Kibana 就像教务处,为管理员(老师和校长)提供直观的界面:
- 展示系统整体运行状况的仪表盘
- 生成各类统计图表(如错误率、性能指标)
- 支持深入分析特定问题
- 设置告警,及时发现异常情况
1. 准备工作
- 创建网桥
elk-net - 下载镜像
elasticsearch:6.6.2 - 下载镜像
kibana:6.6.2 - 下载镜像
logstash:6.6.2 - 下载镜像
bingozb/logspout
信息:版本号说明
实际操作时,建议所有 ELK 组件使用相同主版本号,避免兼容性问题。
2. 运行 elasticsearch
Elasticsearch
Elasticsearch 负责存储日志,并提供强大的搜索功能,比如可以按日期、关键字等条件快速查找日志。
docker run -d \
--privileged \ # 特权模式
--name elasticsearch \ # 容器名称
-e discovery.type=single-node \ # 环境变量
--network elk-net \ # 连接网络
-p 9200:9200 \ # 端口映射
elasticsearch:6.6.2 # 仓库名:标签名
privileged 参数说明
--privileged 以特权模式运行容器,该模式赋予容器几乎与宿主机相同的权限:
- 移除大多数安全限制
- 禁用默认的容器安全隔离机制
- 绕过Docker的默认安全配置
- 授予额外的内核能力
- 提供几乎所有Linux内核能力(capabilities)
- 允许容器执行通常被限制的操作
- 允许访问所有设备
- 自动映射宿主机的所有设备到容器内
- 容器可以直接操作宿主机硬件
参数解释
-e 参数用来传递环境变量:
变量名是 discovery.type 用来控制如何发现集群,本例中只有单个节点,所以变量值是 single-node
端口解释
- 9200 端口:供其他软件或用户与 elasticsearch 通信
验证
浏览器访问
http://IP:9200,如果看到 JSON 信息说明 elasticsearch 启动成功。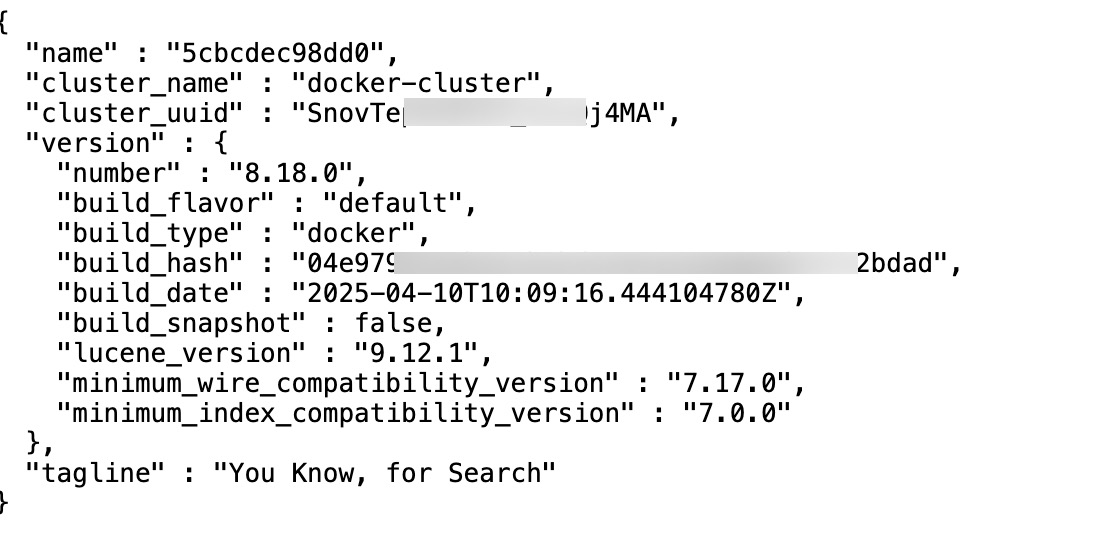
3. 运行 kibana
Kibana
Kibana 提供统一的日志查询和可视化界面。
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
--network=elk-net \
-p 5601:5601 \ # kibana 在 5601 端口提供网页服务
kibana:6.6.2
参数说明
-e ELASTICSEARCH_HOSTS:指定 elasticsearch 的主机地址和端口号-p 5601:5601:Kibana 网页服务端口
浏览器打开 http://IP:5601,即可进入 Kibana 页面。
4. 运行 logstash
Logstash
Logstash 用于接收和整理日志,然后发送给 elasticsearch 存储。
首先准备 logstash 配置文件:
vim /root/logstash.conf配置文件内容如下:
input {
tcp {
port => 5000
codec => json
}
udp {
port => 5000
codec => json
}
}
output {
elasticsearch {
hosts => "elasticsearch:9200"
}
}
配置文件说明
- input 部分:监听 5000 端口,接收 tcp 和 udp 格式的日志
- output 部分:将日志发送到 elasticsearch 服务
运行 logstash 容器:
docker run -d \
--privileged \
-p 5044:5044 \
-v /root/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
--name logstash \
--network elk-net \
logstash:6.6.2
参数解释
-v:将配置文件映射到容器内-p 5044:5044:logstash 对外通信端口
5. 运行 logspout
Logspout
Logspout 负责收集所有容器的日志,并转发给 logstash。
Docker Socket
Docker Socket(通常是
/var/run/docker.sock)是 Docker 守护进程提供的一个 Unix 套接字文件,是 Docker 客户端与守护进程通信的桥梁。docker run -d \
-v /var/run/docker.sock:/var/run/docker.sock \ # 将 Docker Socket 挂载给容器
-e ROUTE_URIS=logstash://logstash:5000 \
-e LOGSTASH_TAGS=docker-log \
--network elk-net \
--name logspout \
bingozb/logspout
参数说明
-v /var/run/docker.sock:/var/run/docker.sock:让 logspout 能访问 Docker 守护进程,获取日志-e ROUTE_URIS=logstash://logstash:5000:指定日志转发目标为 logstash-e LOGSTASH_TAGS=docker-log:给日志打标签,便于后续筛选
6. 使用 Kibana
- 通过浏览器访问
http://IP:5601,打开 Kibana 主界面。 - 选择左上角的 Discover(探索)功能,点击 Create index pattern 创建索引。
- 在 Index pattern 中输入正则表达式过滤日志,然后点击 Next Step。
- 选择时间列(可跳过)。
- 回到 Discover 页面,就能看到收集到的日志了。
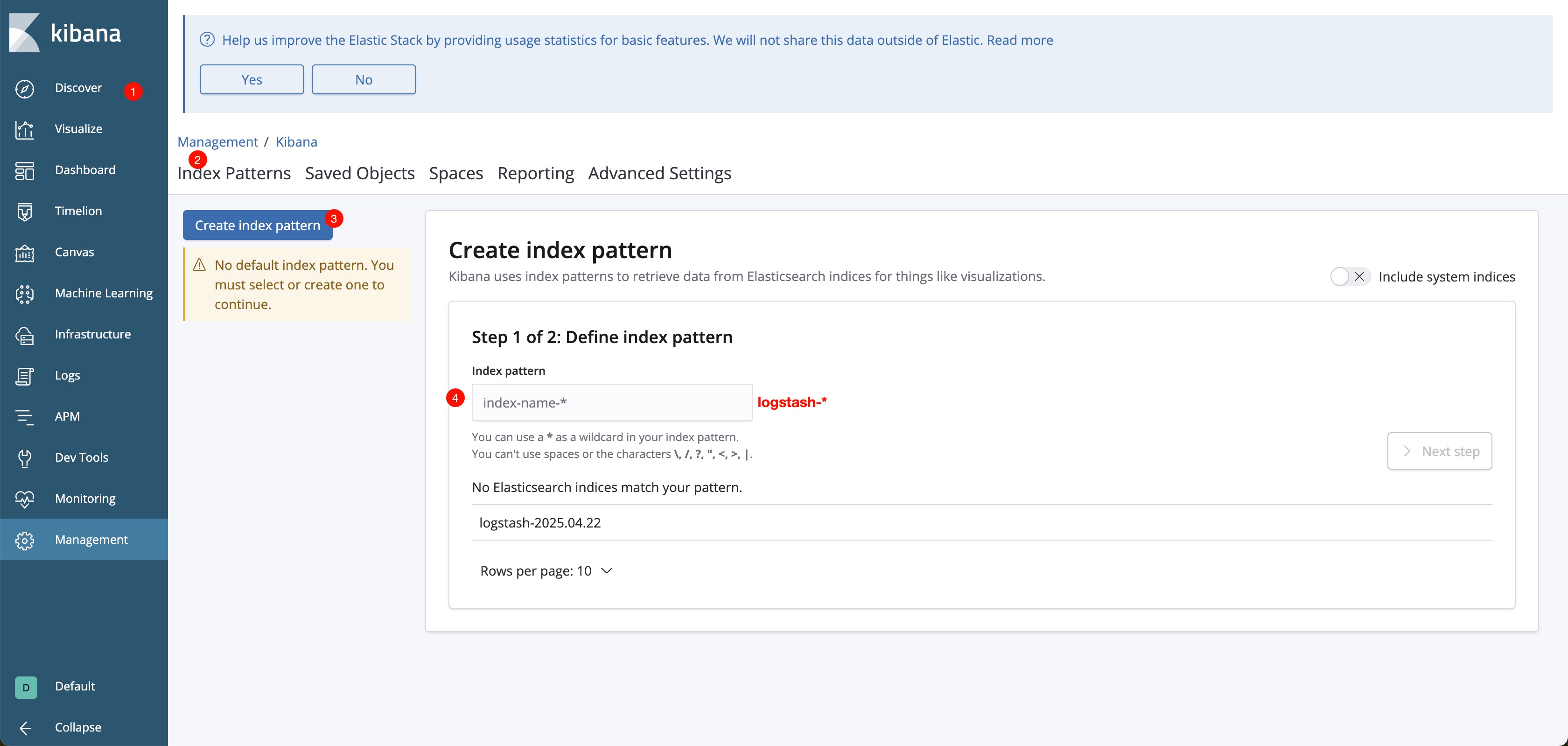
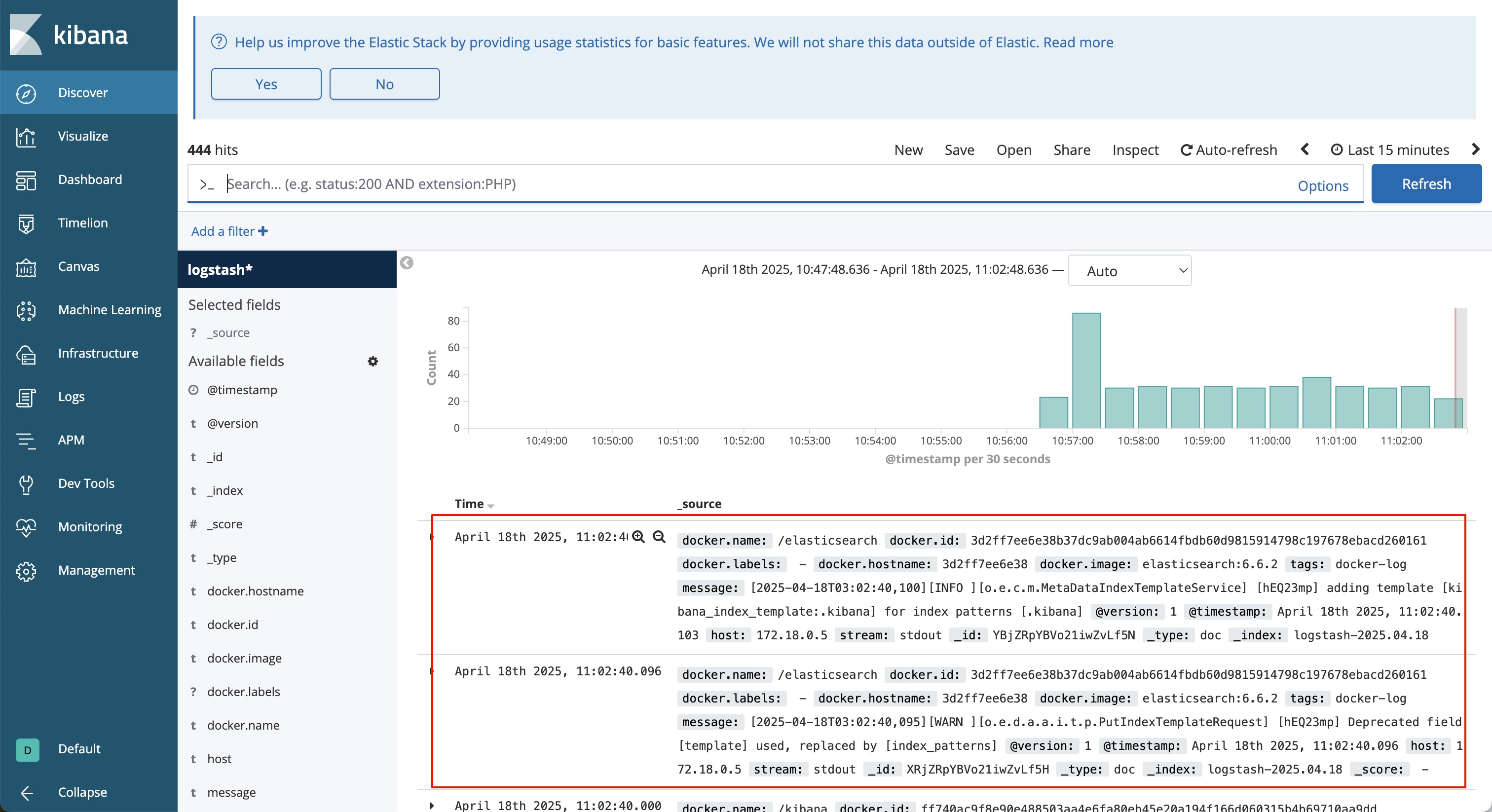
7. 运行测试容器
可以用下面的命令启动一个测试容器,它会每秒输出一条日志:
docker run -d --name python-logger python:3.9-slim sh -c 'python -c "import time, sys; [print(f\"日志条目 #{i}\", flush=True) or time.sleep(1) for i in range(1000)]"'再运行之前使用过的 supervisor 容器:
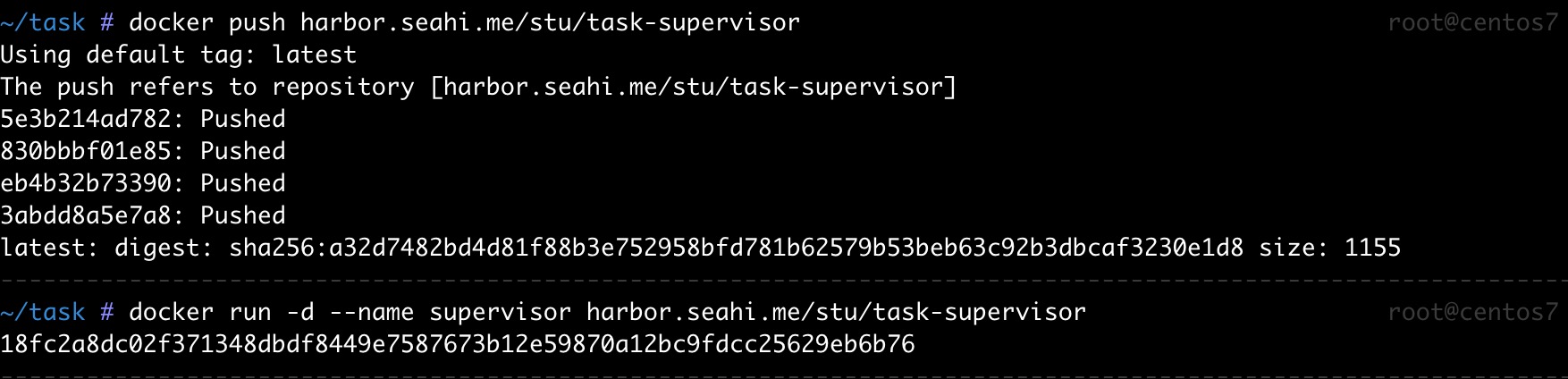
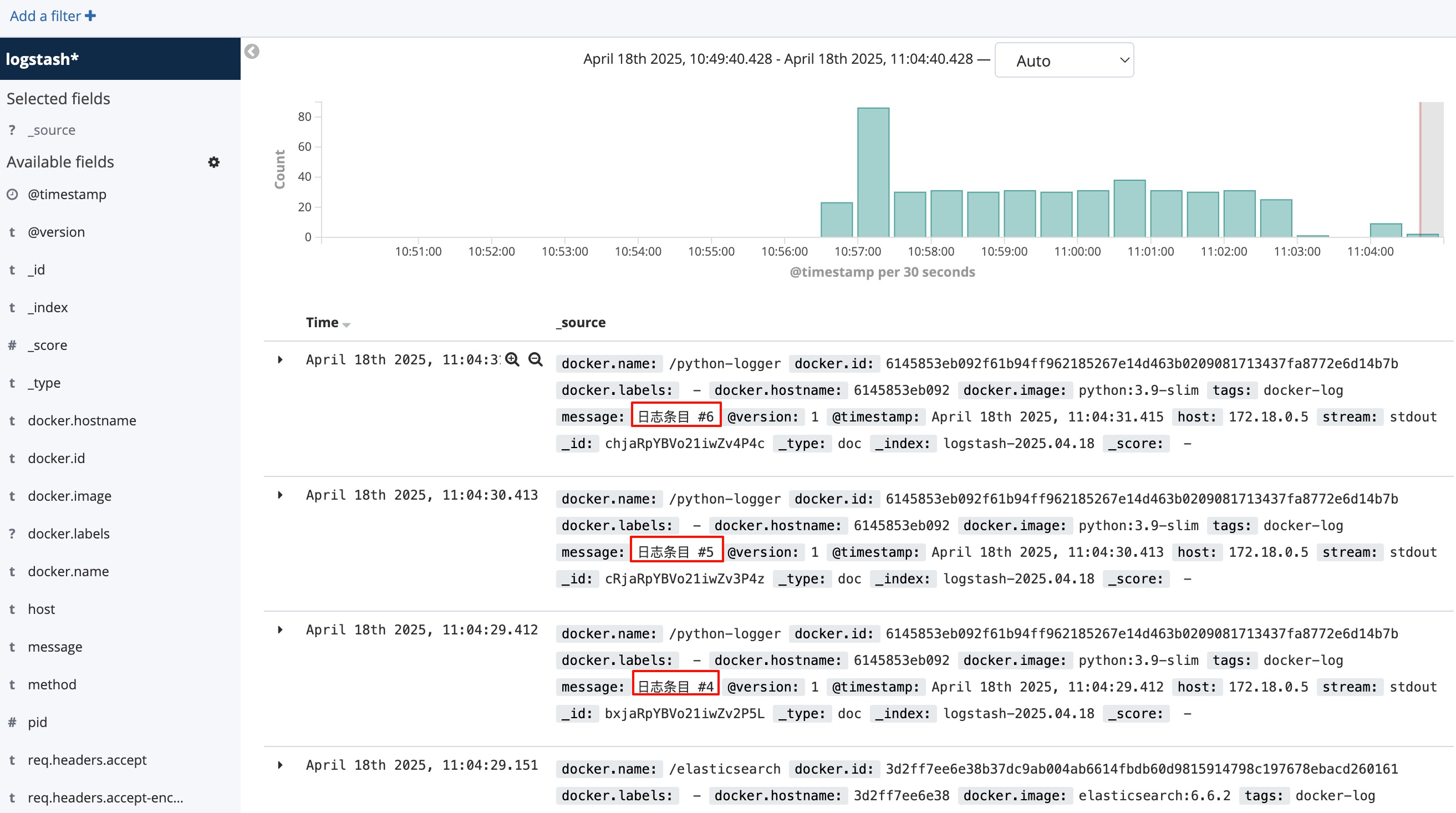
此时回到 Kibana 页面,应该能看到实时新增的日志:
成功:日志收集完成
至此,Docker 日志已经通过 ELK 系统实现了集中收集和可视化。
任务四:日志可视化
1. 容器活跃饼图
了解不同容器的日志占比,识别系统中最活跃的容器。
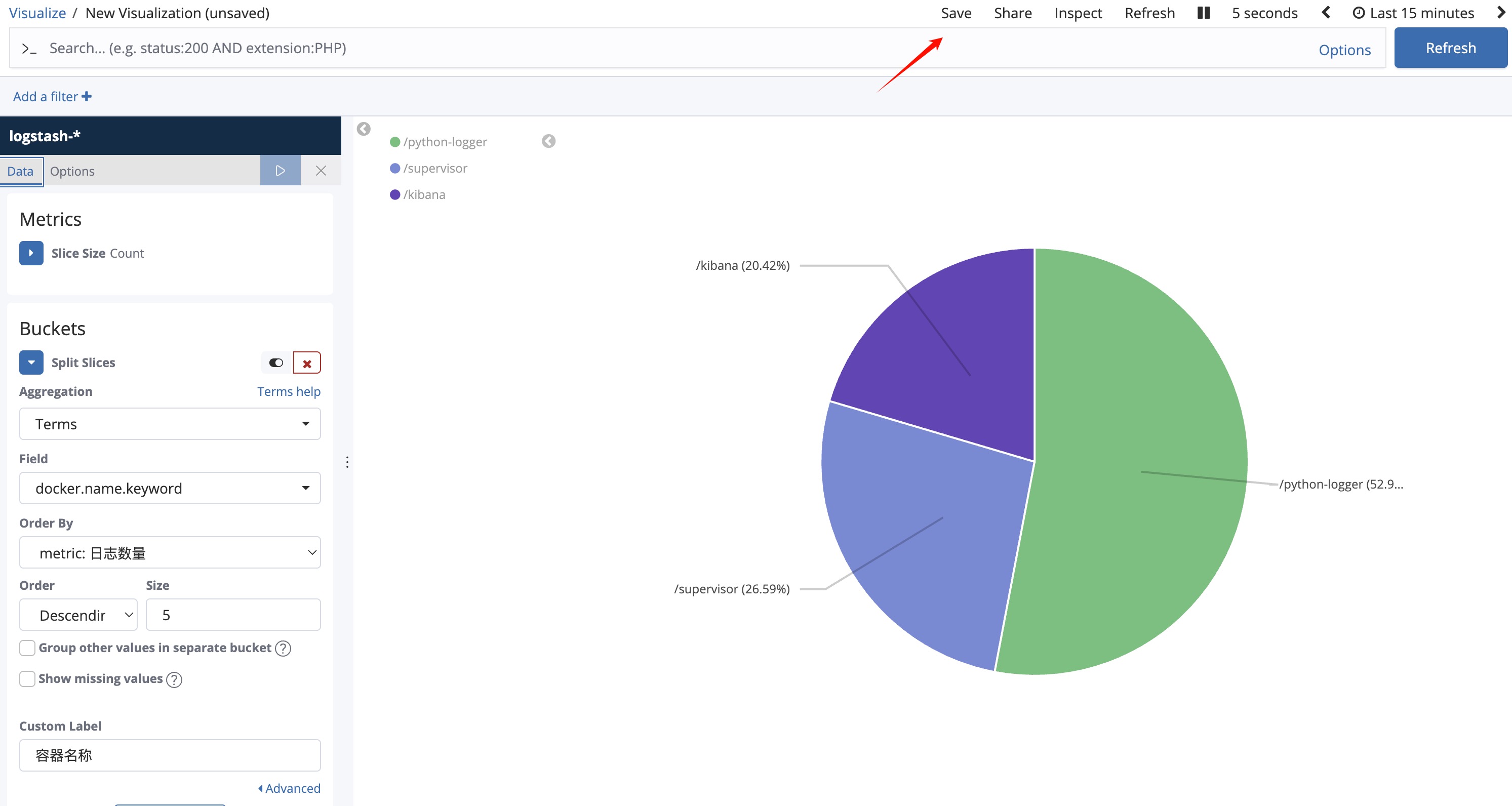
Step 1 创建饼图
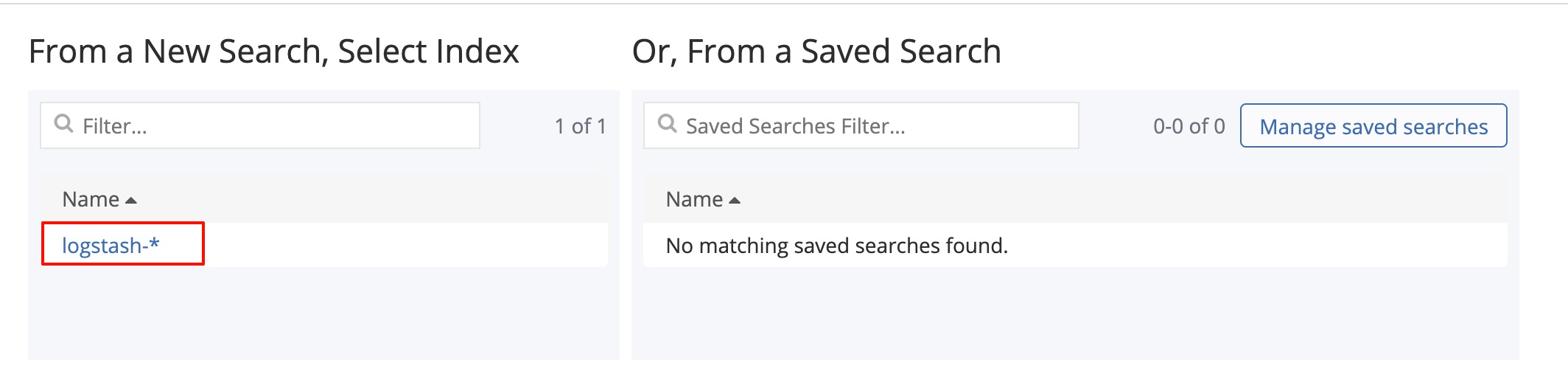
出现以下界面:
- Metrics 定义要计算什么,默认有一个Count(数量)
- Buckets 定义如何分组
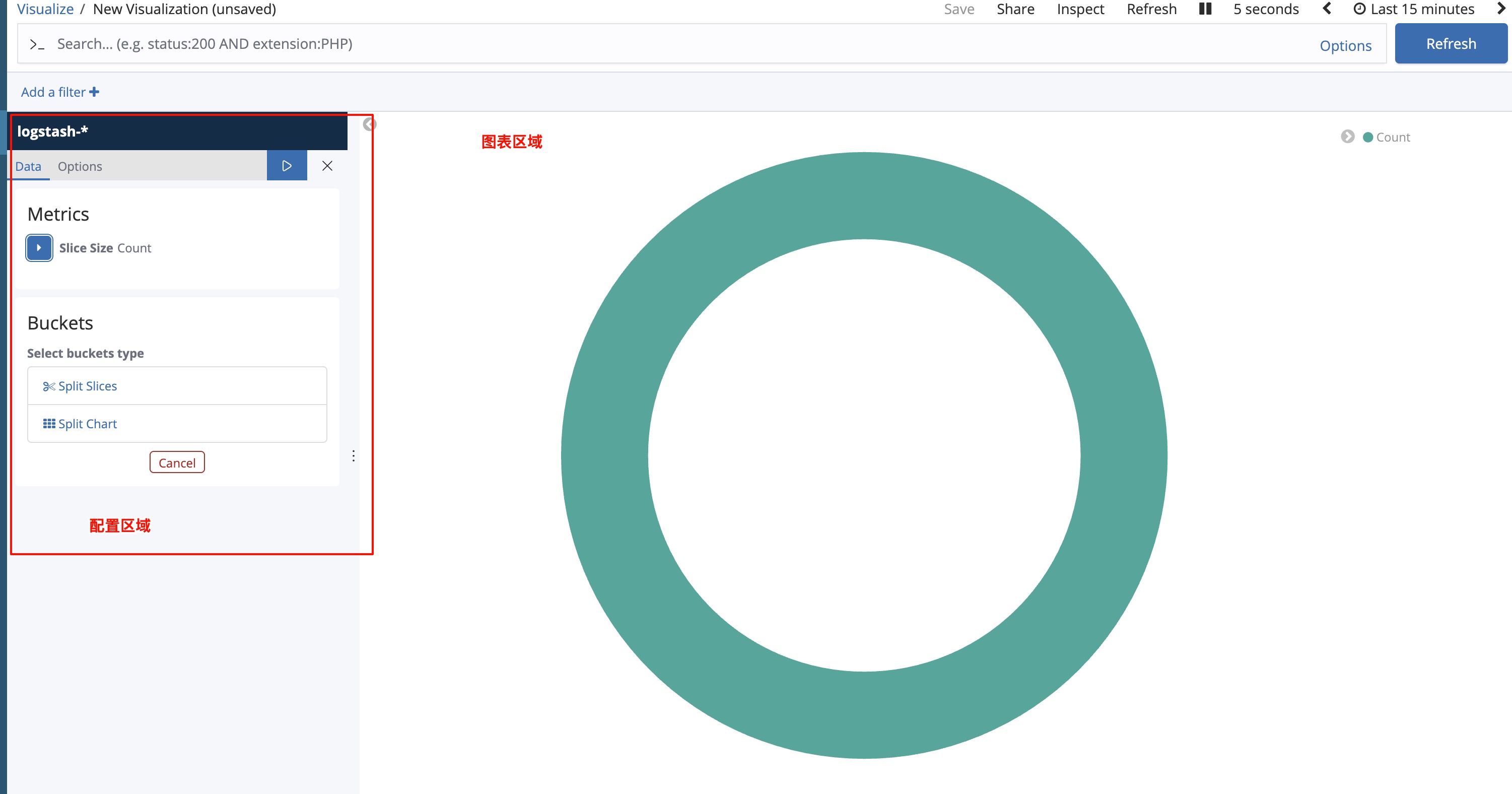
- 在 Metrics 部分,您会看到一个默认的 Count 指标
- 保持这个默认设置不变,因为我们要统计每个容器的日志数量
- 如果您想修改标签,可以点击 Count 展开设置,在 Custom Label 字段中输入 “日志数量”
接下来设置分组 Buckets
- 在 Buckets 部分选择 Split Slices 选项(这将创建饼图的各个切片)
- 在 Aggregation 下拉菜单中选择 Terms
- 在 Field 下拉菜单中,选择 docker.name.keyword
- Size 设置为
10(显示前10个容器) - 可以在 Custom Label 中输入 “容器名称”
- 点击右上角的 ▶ 按钮应用更改
Step 2 配置 Options
- Donut 切换饼图和环图
- Legend Position 控制图例位置
- Show Tooltip 控制鼠标浮于上方时是否显示信息
- Show Labels 是否直接将标签(容器名)显示在图表中
- Show Values 是否显示数值
- Truncate 截断文本
Step 3 作业
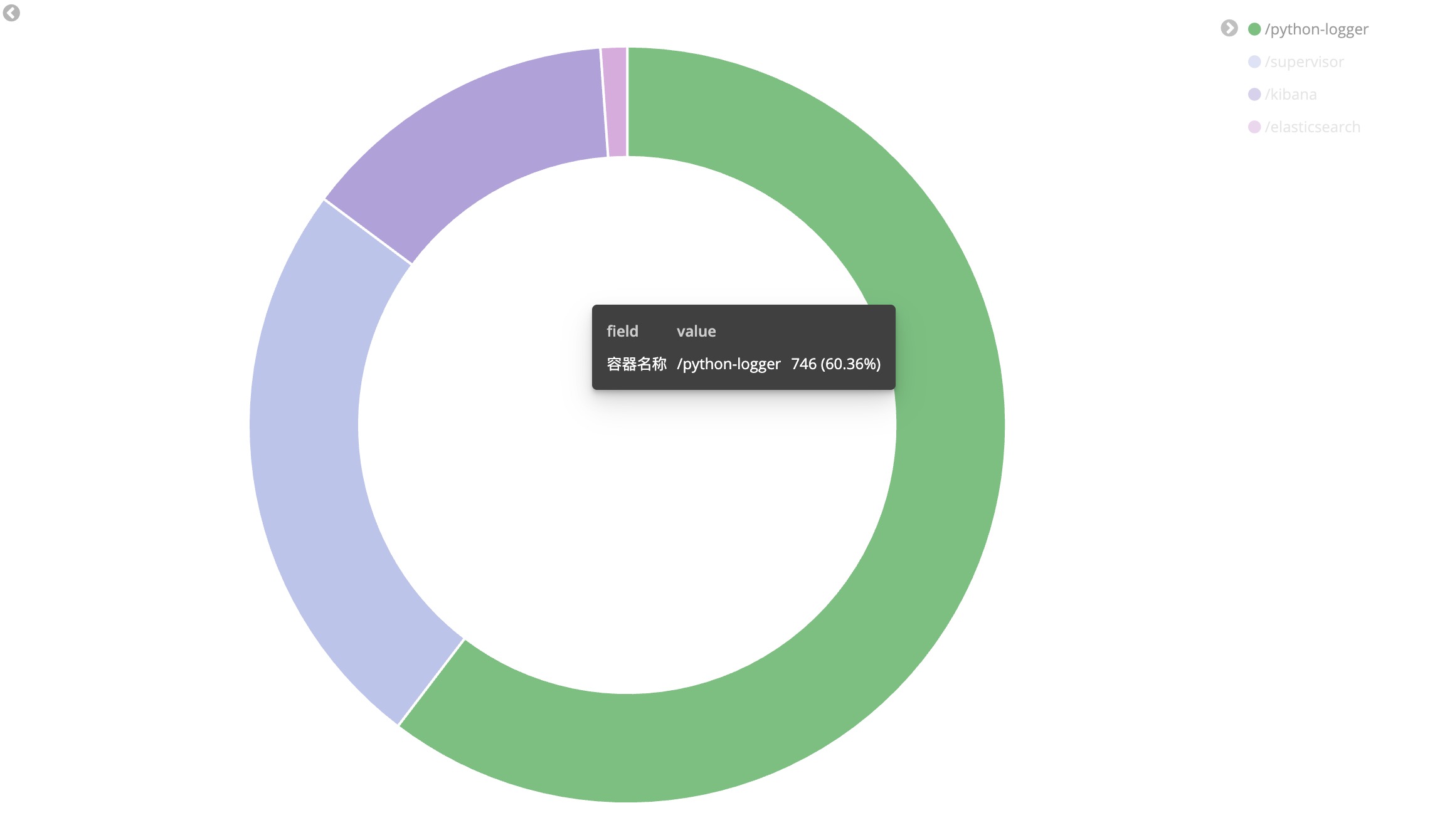
请调整参数画出以下饼图:
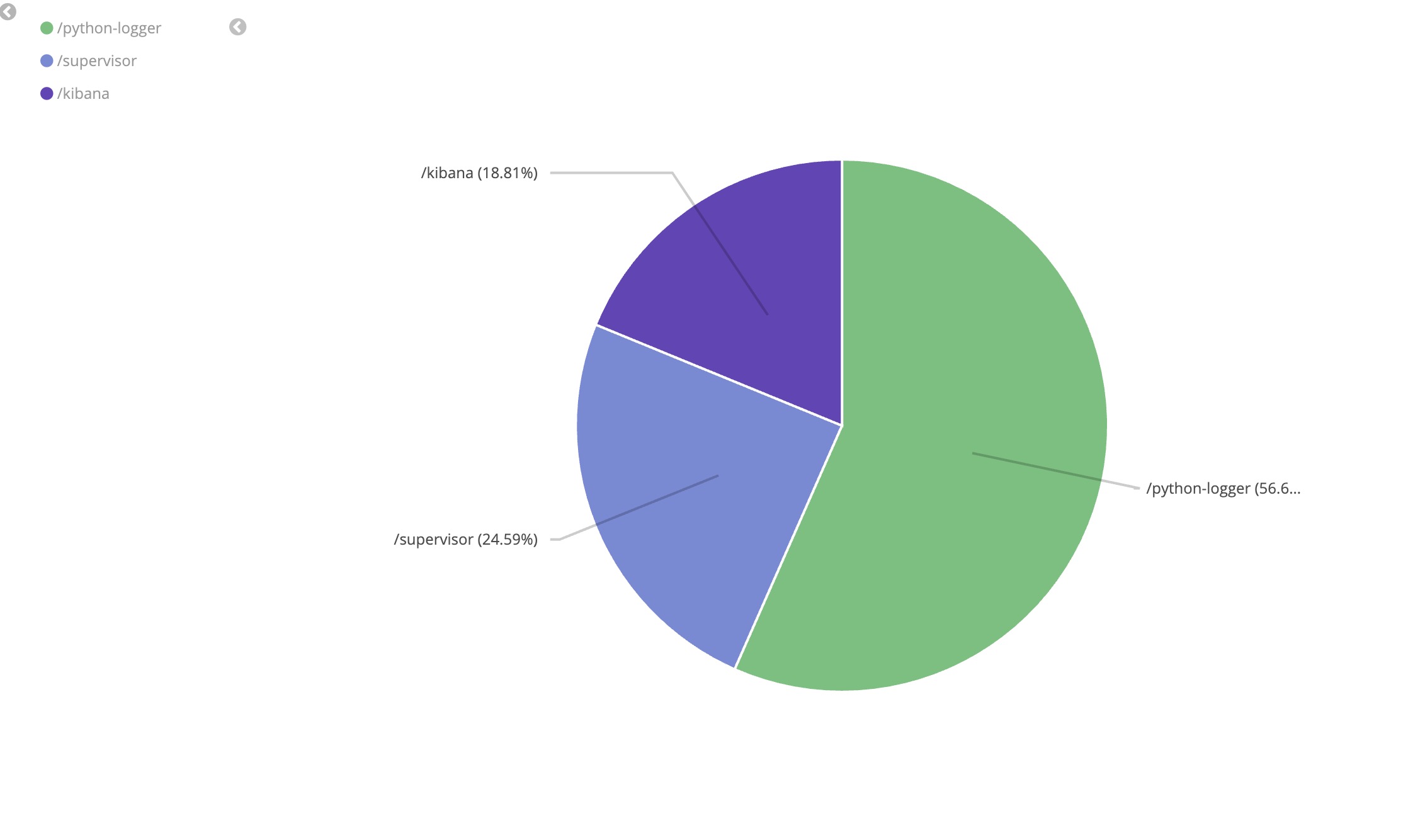
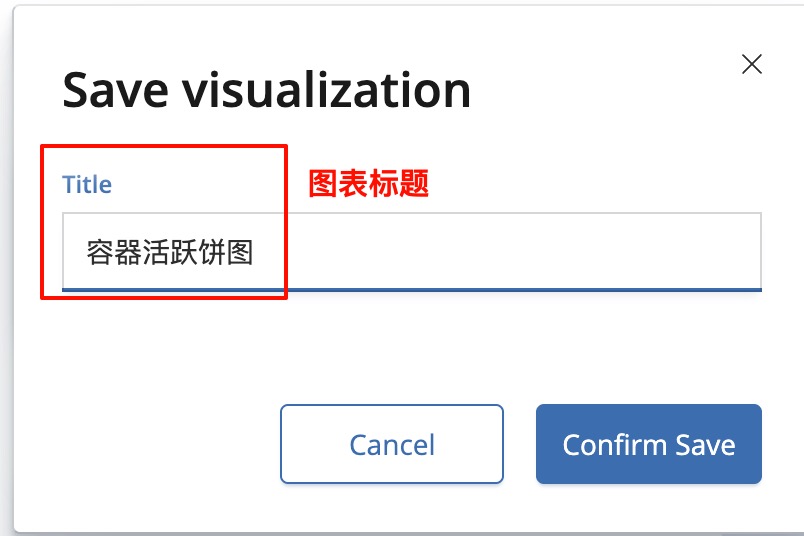
全部配置完成后,不要忘记点保存!
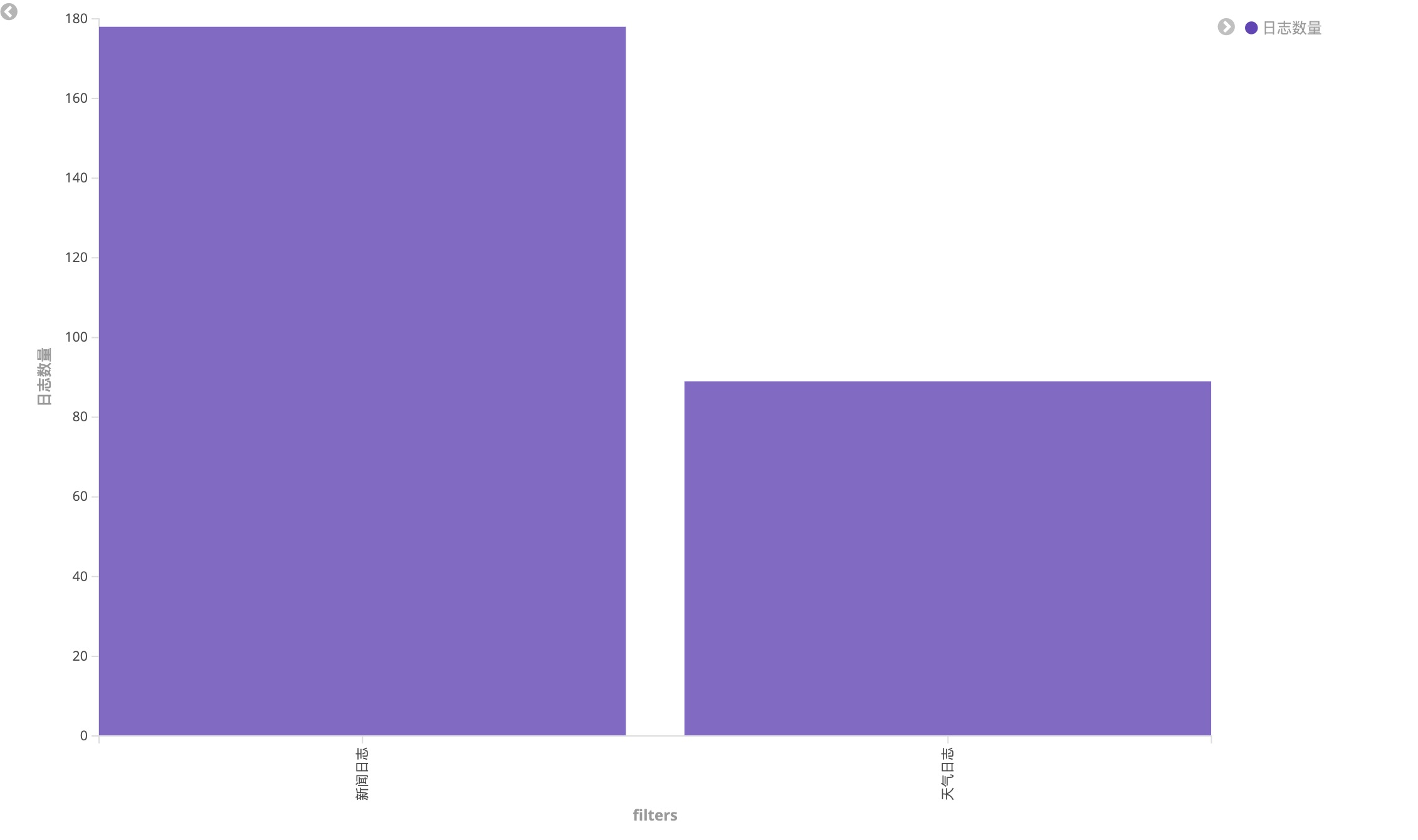
2. 新闻与天气日志数量
对比 supervisor 容器中的新闻和天气日志数量
- 创建数据表可视化(Vertical Bar)
- 在页面顶部的查询栏中,输入筛选条件:
docker.name: "/supervisor" - Y 轴使用默认的 Count,增加标签为“日志数量”
- X轴选择 Aggregation 聚合为 Filters
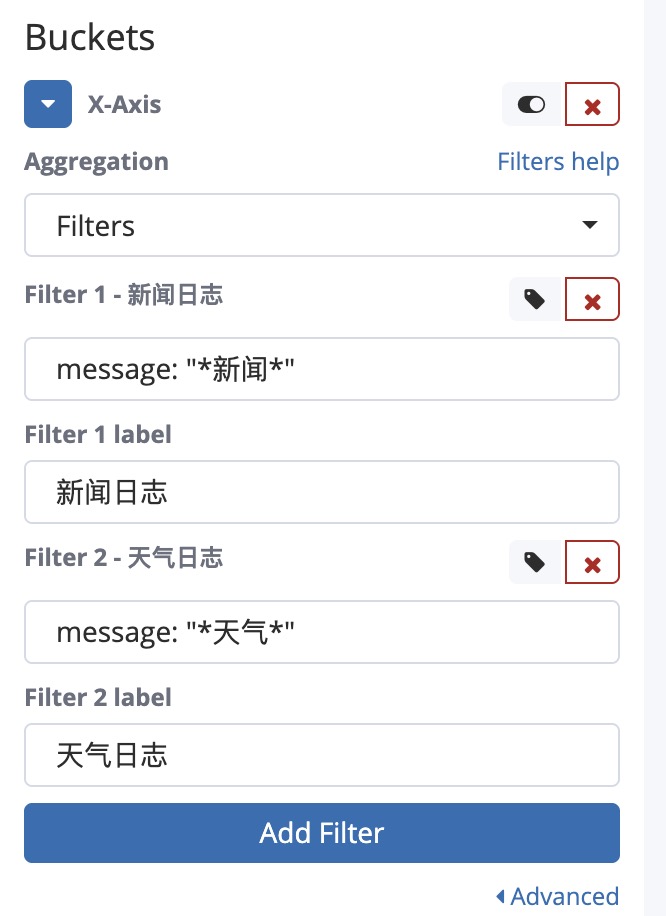
最后的图表如下: